How to import data without writing code


Introduction
It’s hard to overestimate the importance of data in modern web development. Most applications these days collect, store and serve data to help users achieve their goals faster and easier. This is why software engineers regularly solve the problem of data import for their applications. In this blog, we will be looking into simplifying this process by reducing monotonous repetitive tasks engineers deal with while implementing the import. Our tool of choice for achieving this goal will be AWS Glue DataBrew.
Problem
At Roam Digital, our engineers commonly face the task of importing data into a database, which - in many cases - can be a rather bespoke job that requires some custom development. In many projects, however, the data import is not a core product feature, so we want to get it just right, and to shift our focus to tasks that add more business value.
An example could be importing and transforming JSON files on schedule, to be able to serve it through REST or GraphQL API. Think of a team working on a “bush fire alerting” application that consumes data files from an external datasource (e.g. Weather Data Services here in Australia), re-groups the forecast records by location and then stores that in a database.
One of the common approaches to solving this in the AWS cloud is creating a Lambda function that is invoked when a new file lands in an S3 bucket. The Lambda function reads the file, parses the data and saves it to a database. At scale, a number of files might be processed simultaneously:
Figure 1. Typical cloud-based data import pattern
Some of the issues with this solution implementation are:
Data mapping. Manual and potentially error-prone process of mapping JSON fields to your database entities.
Data transformation. The raw source data might need to be processed before persisting it to database, so a custom transformations logic (e.g. cleaning out invalid records; aggregating records; extracting values from an array into separate records, etc.) might be needed.
Data size. Lambda functions are designed to run for a short time only (15 minutes max at the time of writing this article) and can only process a certain amount of data.
Error handling. If the Lambda function crashes, you might want to re-run it, so a retry mechanism is needed for this.
Partitioning. In cases when there is a lot of data to import, implementing partitioning might be a good idea too.
While this list is far from describing every aspect of data import implementation, it illustrates why it can quickly get out of hand and become a bigger piece of work, distracting the engineers from delivering potentially more important product features.
Solution
Data import can be seen as a special case of a wider class of engineering problems known as ETL (extract, transform, load). ETL is widely adopted in data warehousing, it is well-described, and there are several existing solutions available on the market.
AWS Glue DataBrew
One of the most interesting ETL services in the Amazon cloud is AWS Glue DataBrew (or simply DataBrew). While AWS positions it as a data preparation tool for data analysts, it perfectly addresses the problem of automating tedious and risky tasks of data import implementation.
Overview
Let’s have a quick look at a sample DataBrew project:

Figure 2. Sample AWS Glue DataBrew project. Source: https://aws.amazon.com/glue/features/databrew/
DataBrew extracts a sample of your data (500-5000 rows) and automatically parses it into a tabular view. It also displays some handy data analytics (data cardinality, min and max values, value frequencies and more) with the help of artificial intelligence and machine learning algorithms running under the hood.
Depending on your target data format, you might choose to perform several data cleanup and transformation operations against the data sample (like “Merge columns” on the screenshot above).
When the data looks right, a job can be generated from the project, so the transformations can be applied to the whole input data source and loaded into the output location.
How It Works
Let’s have a quick look into what’s required for a simple JSON files parser implemented as a DataBrew job.
1. Configure a Dataset
Your JSON files need to be in an S3 bucket for DataBrew to be able to read them. After the job is created, the new files to be imported should appear in this bucket too.

Figure 3. Connecting Amazon S3 dataset to DataBrew project.
2. Configure an IAM Role
You’ll need to give a role to the job. This is the last compulsory step, and we can create a project after this:

Figure 4. Configuring IAM role for DataBrew project.
3. Transform the Data
This is one of the core features of DataBrew. A lot of transformations are available out of the box. Some of the useful ones include:
Filter values
Rename column
Remove column
Unnest
Change type
The goal here is to convert the input data sample to the target format through a chain of transformations.
Example
The transformation step is particularly interesting as it substitutes the mundane engineering work. Let’s have a closer look at the source data for our bush fire alerting application:

Figure 5. DataBrew dataset preview.
As we can see in the screenshot above, the source data files contain hierarchical data structure with forecasts grouped by Australian states and territories, and then by dates. Since we are interested in fire danger forecasts only, the transformations would involve ungrouping this data and filtering by the forecast type. After removing all the unnecessary columns, the sample dataset might look like this:
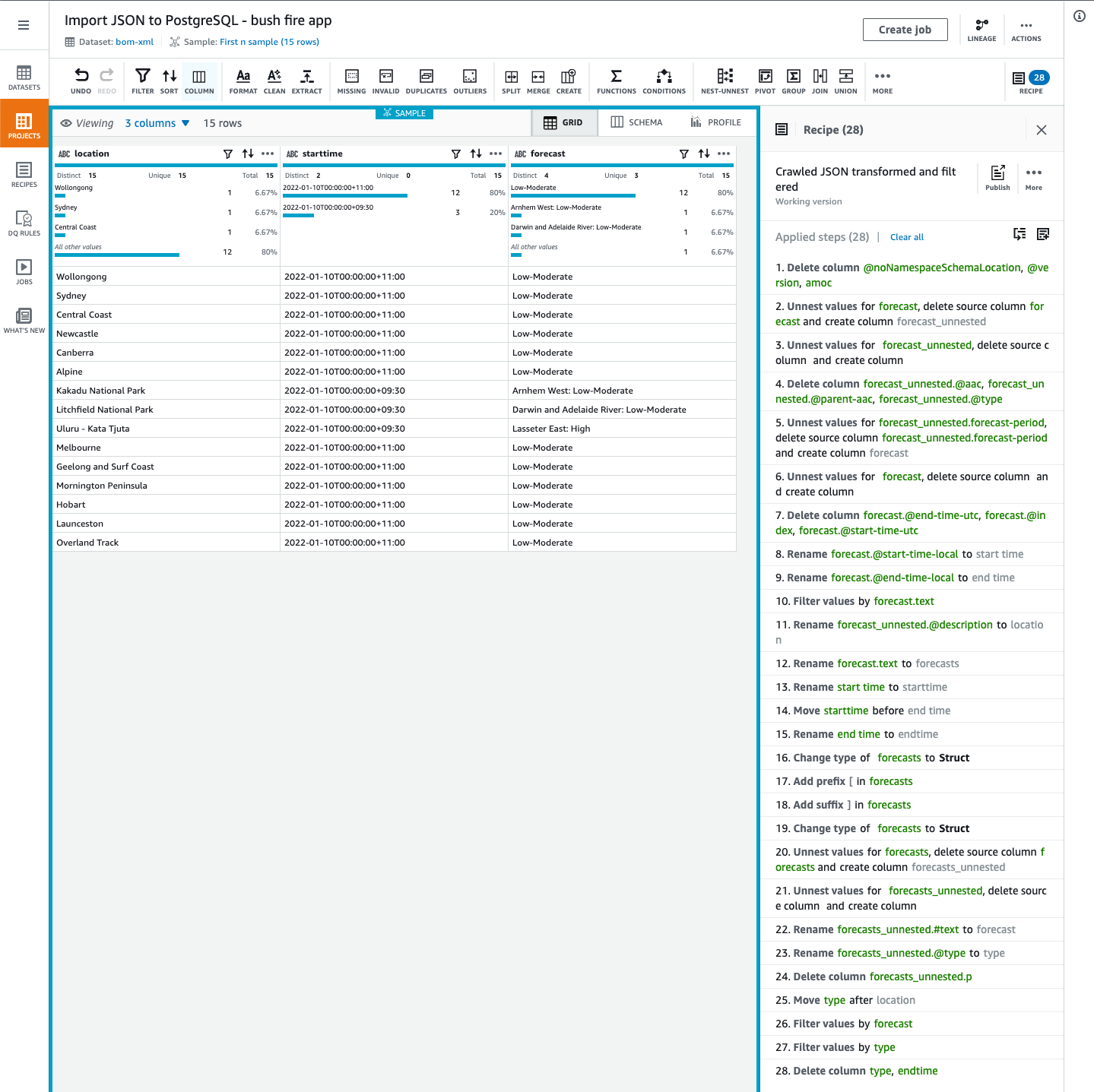
Figure 6. DataBrew project with a transformations recipe.
4. Create a Job
Creating a DataBrew job is pretty straight-forward, and mostly focused on configuring outputs for the job. For the sample project, we will use a pre-configured JDBC connection pointing to Postgres database instance in AWS RDS service.
The output for each run would be stored in a new table with databrew prefix:

Figure 7. DataBrew recipe job output configuration.
5. Schedule the Job
Scheduling is out of scope of this blog and is well described in the documentation.
DataBrew Recipes
Congratulations! You have just created a new DataBrew job that parses data at scale, supports partitioning, enables reruns upon failures, and bookmarks processed files automatically; all without writing a single line of code! This is a good start, though in a production situation configuring a number of jobs with their data sources and transformations might be needed.
The next natural question is: how could we reuse the transformations? In cases where there are identical or very close input formats, it may be useful to export and import the transformations between the projects. This feature is called Recipe and it allows exactly this. When a recipe is created, it can be used to create another job even without creating a project:
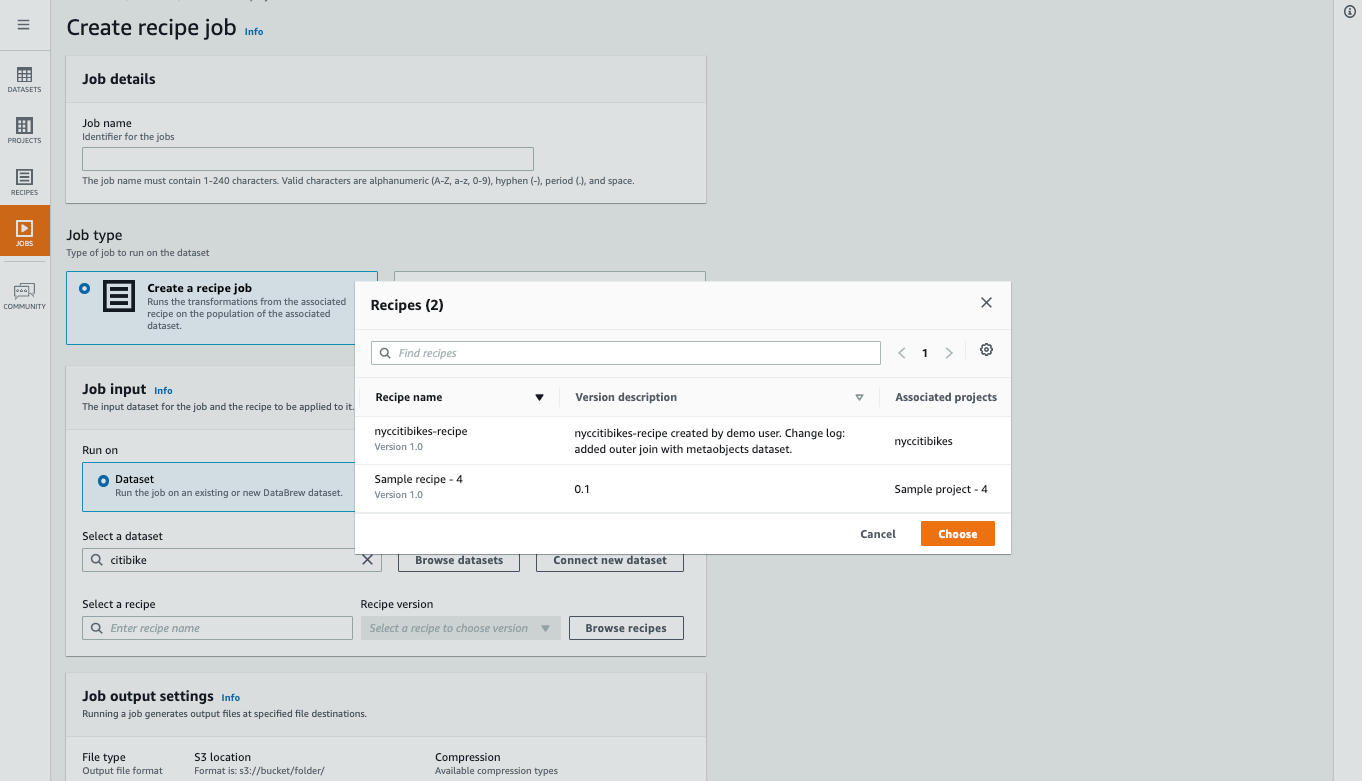
Figure 8. Creating a DataBrew job from recipe. Source: https://aws.amazon.com/glue/features/databrew/
Recipes are versioned and stored in a human-readable format, so it’s easier to track changes:
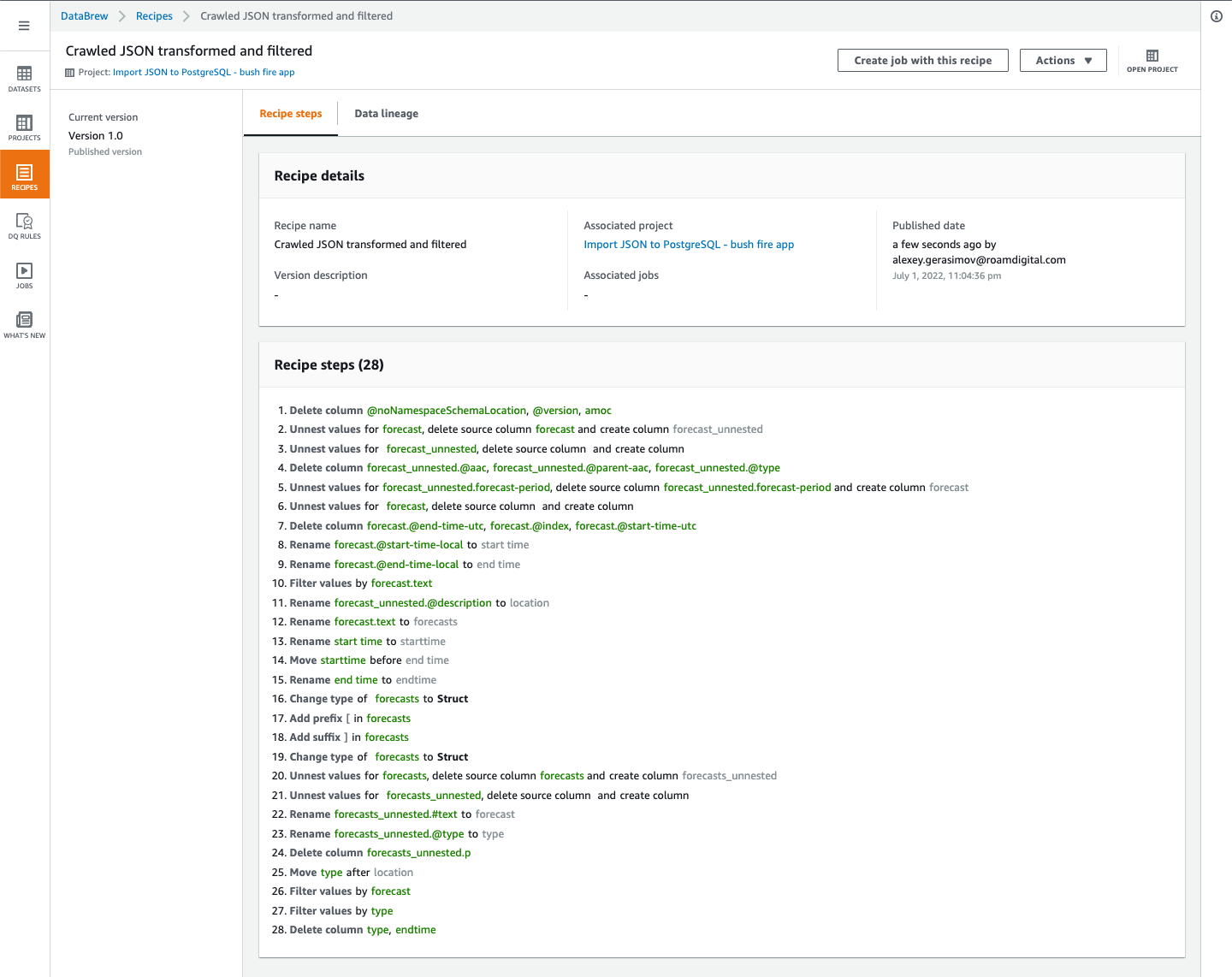
Figure 9. Saved DataBrew recipe view.
and even exported in JSON format, so that we can source control them in Git:

Figure 10. DataBrew recipe exported as JSON (snippet).
Supported File Formats
Let’s have a brief look at some more technical capabilities of DataBrew.
DataBrew supports a decent list of input and output file formats. If you need to import large CSV files or transform Excel to JSON at scale, DataBrew has got you covered:
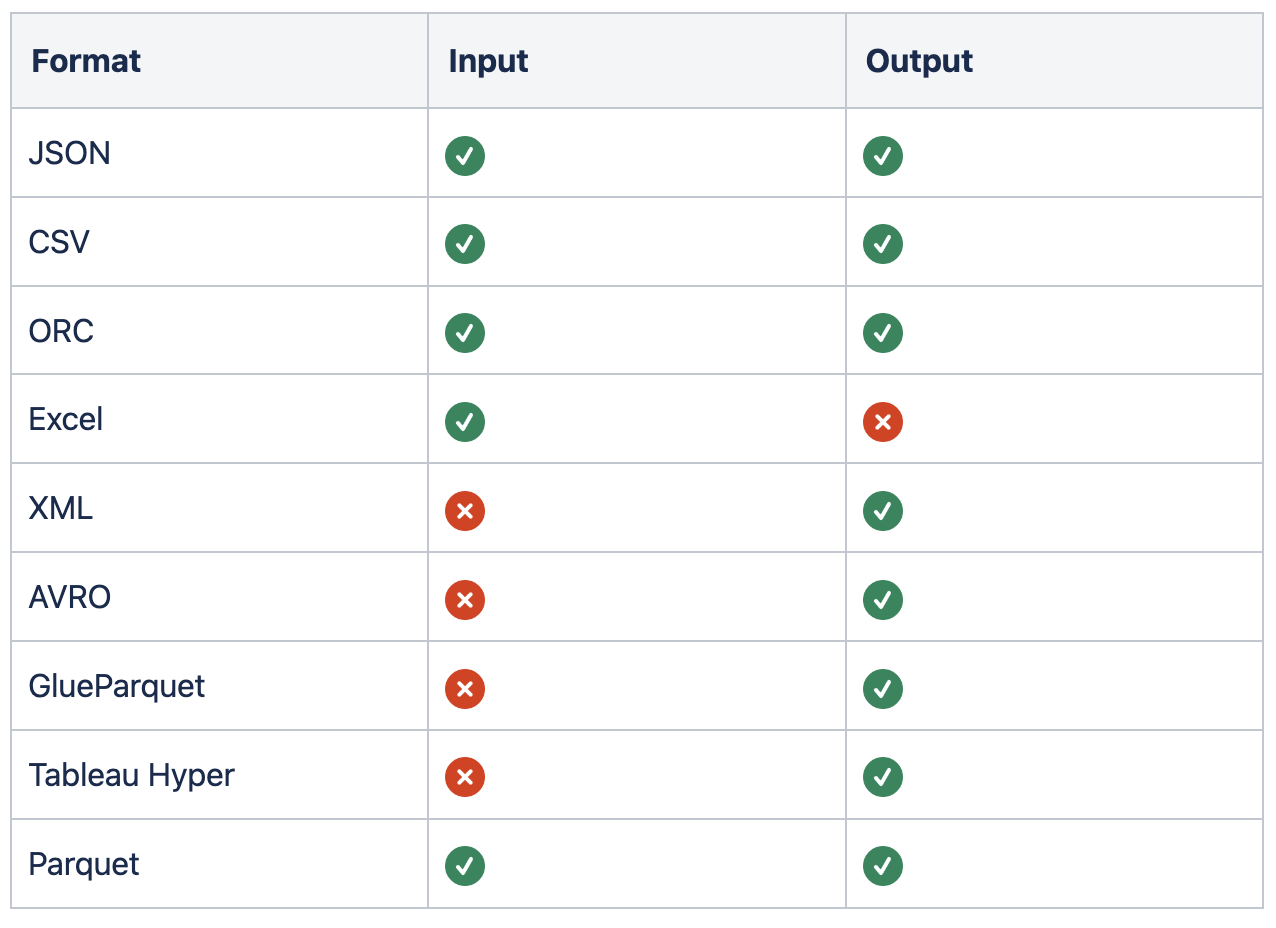
Based on the fact that DataBrew supports Amazon S3 as both input and output locations, one of the additional use cases is converting data from one format to another, or just changing data schema. An example could be removing records with empty/corrupted data from the data source.
Supported Database Types
If you are importing data into a relational database like Postgres or MySQL, or Amazon Redshift, DataBrew supports them out of the box:

When using DataBrew with JDBC database hosted in AWS RDS instance, additional setup steps might be needed:
Creating JDBC connection in AWS Glue service;
Creating a VPC endpoint for AWS Glue.
This configuration process is described in the documentation here.
Cost
To make an informed call on using a cloud service as opposed to a bespoke and custom implementation, your organisation should be aware of the costs involved and consider the following:
With pay-as-you-go approach, an organisation saves on the infrastructure when it’s idle while probably paying a little extra when the resources are actually utilised.
The combined costs of implementing in-house built solution and operating it at lower costs vs. short-cutting the development and potentially overspending on the third-party tool operation in the long run.
As AWS Well-Architected framework advises, a fully cost-optimized workload is the solution that is most aligned to your organization’s requirements, not necessarily the lowest cost.
Below is the breakdown of the DataBrew costs in Australian dollars as per mid-2022 (see more here):
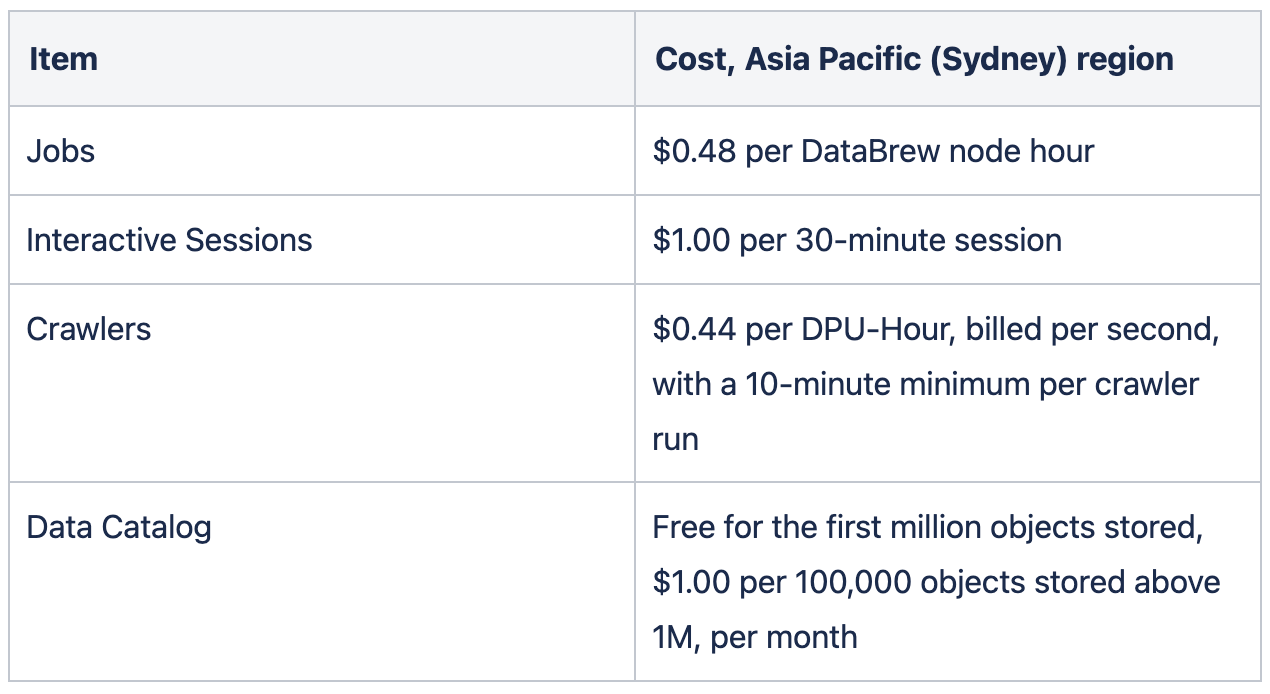
As often with cloud services, it makes sense to consider DataBrew when the time-to-market is a critical metric of the project success, and building a custom solution involves significant engineering efforts.
Limitations
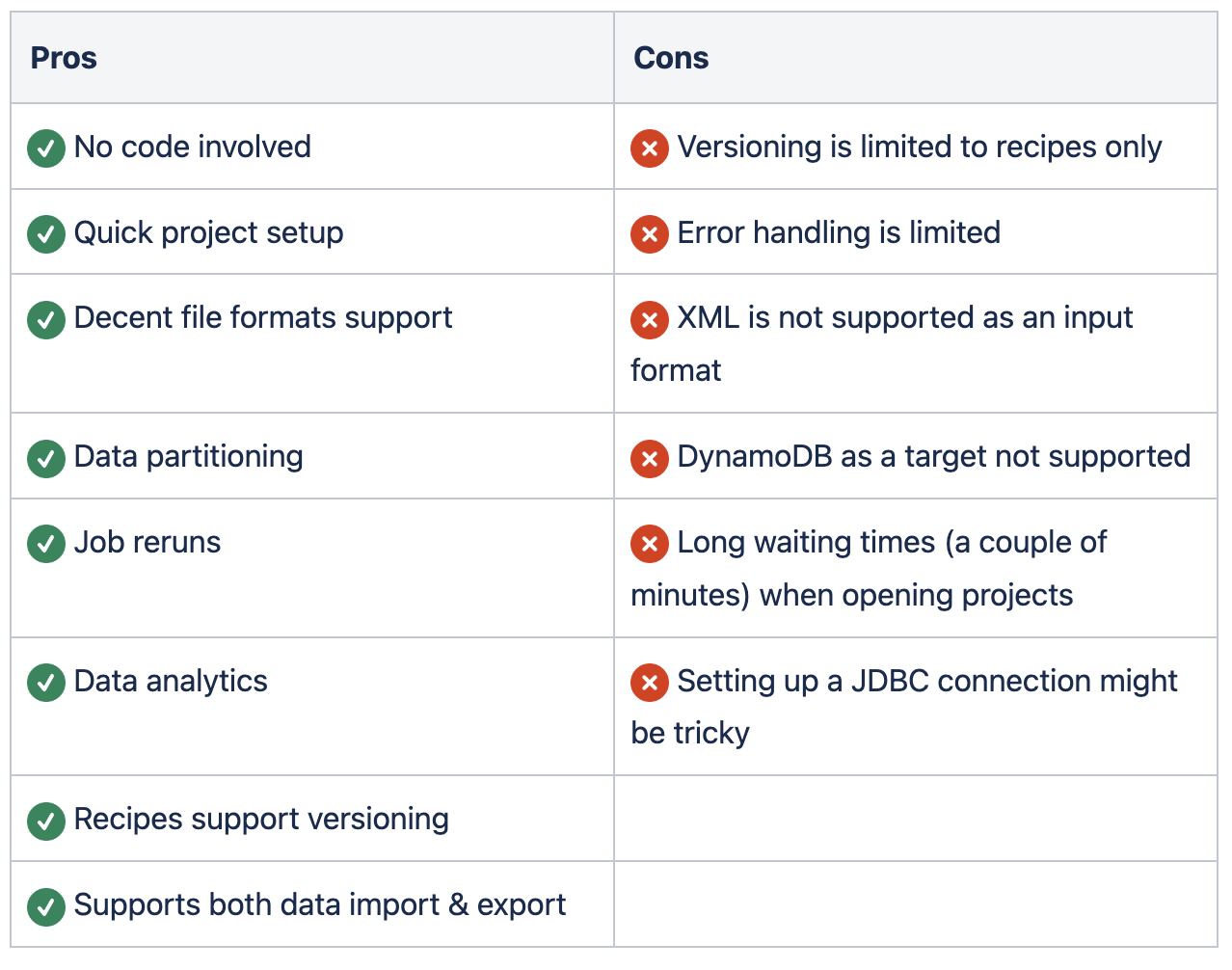
There are no silver bullets in software development, and AWS Glue DataBrew is no exception. Since DataBrew is a managed service with rich functionality, a lot of its features are opinionated. This helps to simplify usage of the service at the cost of reduced flexibility.
The table below shows some of the limitations that you should keep in mind when deciding on adopting DataBrew in your tech stack:
Summary
Getting data import right is important, and with AWS Glue DataBrew, it becomes as simple as never before. Out of the box, this managed service provides surprisingly rich functionality that might be just enough for small to medium projects that import data:
Simple AI-powered data mapping;
Rich list of built-in transformations;
Versioned transformation recipes;
Auto-scaling jobs to match your data size;
Partitioning and bookmarking;
Support for a variety of data formats and database vendors;
On top of that, no coding involved!
Before adopting DataBrew, it is also important to keep in mind its limitations. In this article, we looked at some considerations like costs, infrastructure as code support and some configuration “gotchas“. At the end of day, DataBrew is yet another powerful tool for an engineer to have under their belt - and knowing its pros and cons will only help in choosing the right tool for the job.
Share