Guarding against data poisoning by storing provenance alongside application data


Introduction
In any application there’s always a way to store the the current state of things. Like “I’ve seen this movie before.” for Netflix or “I’ve rated this stupid thing as 1 star as it broke the day after it arrived.” In these kinds of applications, developers write the code to handle how these states are stored. And code, despite their creators' best intentions, are more like humans in that they, too, err. Developers are quick to fix these problems and often these are resolved quickly. Sometimes, though, some small errors are overlooked and persist long after the original developer has left and when that happens they are difficult to find. What I will be discussing in this blog post is a nifty way for developers to make sure these errors are easy to isolate and track.
Who is this for?
If you’re a backend developer or someone managing the persistence of your application like a full stack dev then this blog post is for you. If you’ve experienced data related bugs, then this blog is 100% for you.
What's the problem?
Let's say you're writing code and you've had a few releases in. Have you ever had a problem where someone added and removed a database migration? Sometimes a database migration breaks some of your data but the next release fixes it. What happens to the data that was somehow missed and wasn't cleaned up?Usually the pull request comes with a script that runs on the whole database to get it to a state where the bad migration PR never happened but what if there's a bug on that revert and your Production data is now poisoned?
For example:
Release 1.0 had a bad migration that wasn’t supposed to be in there and changed all of the URLs to user photos to end with a JPG.
Release v1.1 was supposed to have a revert of this migration but we’ve already had the code in production for a while now. If the migration was badly written, then the revert would only target the set of users in existence before Release v1.1.
The poisoned data would be the set of user URLs created after v1.0 and weren’t fixed by the revert.

how a poisoned state occurs
I can hear you thinking, “Well that’s easy to debug and fix. Just find the poisoned data and run another migration.” But in this scenario, you’ve had bad data for quite a while now. Let’s say a few weeks of minor releases and one major release. How far did the effects of that bad data spread? What else did it touch? Is analytics impacted in any way? Sure, a quick fix is easy to do for the ones you find but if your application has a complex interdependency of data, how sure can you be that you’re fixing the right set?
I want to stress that this is hypothetical situation that I made up and you probably already have a good solution in place that can deal with this specifically. There are multiple categories for data poisoning but I just want to focus on this scenario for the moment. The next blog post will expand the scope of discussing provenance and its benefits to the wider ecosystem.
What's the solution?
Store provenance alongside your data.Provenance, in this case, is metadata that shows why and how the data was produced, where, when and by whom. There are a number of other solutions that can fix bad migration problems but this simple framework will help down the line when you grow your application and incorporate other data sources or systems.
One example of provenance that may be more familiar:
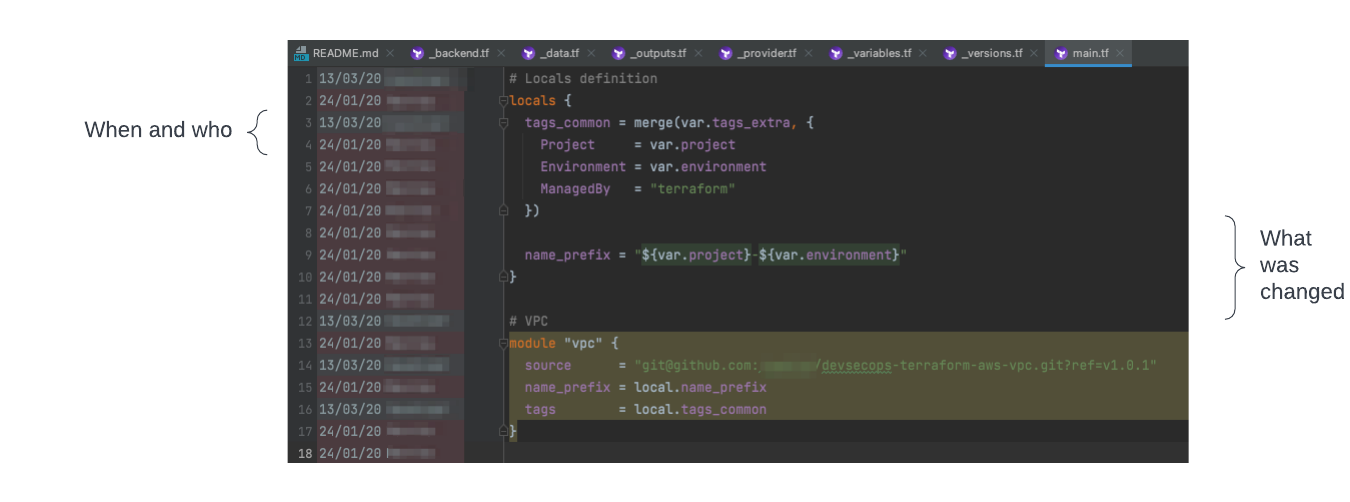
git blame
I can still remember the days before git blame or even versioning. It was tough to navigate the code and try to understand how to fix the bug without reading the whole thing. Now it’s a lot easier to understand the context for a group of code changes. You have when it was done, by whom, what lines were changed, and even a link to a ticket that has a lot more discussion.
If you can use this same approach with your data, you’ll be seeing the same improvements.
Steps (or What is and How to store Provenance)
I’ll be laying out some example instructions below on figuring out what’s important to your whole system, storing that metadata alongside the application data, and querying/alerting so you can figure out what’s wrong.
Review and understand the reason and processes for creating your data.
Again: why and how the data was produced, where, when and by whom.
For example: A social media post created your data so it should look like:

2. Maintain the changes as metadata across the lifecycle of use.
a)If another service within your application changes the data in any way, add that process to your provenance

Implementation
Based on the provenance data you could implement a fix if you’ve noticed some poisoned data like this:

manual isolated extract and fix for bad migration
(It’s easy to find only the poisoned data and create a fix without impacting the wider application. There’s no need for a complex revert and release.)
The following shows an ideal Production environment with automated systems to perform the checks and fixes:

automated fix for poisoned data (no release needed to fix the data)
Storing provenance gives you an easy way to understand what set of data you need to extract and run a script to fix them. It also gives you a timeline of events and from there you can even trace why and how such problem arose. Down the line, for any legal reasons, you could even use this timeline to prove or disprove any issue.
You’ve provided NoSQL examples, what about relational approaches?
For relational provenance you typically store these in a different table that tracks the rowID for each entity. Here’s a system wide provenance schema example:

Here’s a table specific provenance schema example:
TABLE_NAME: SOCIAL_MEDIA_POST_PROVENANCE

What about the overhead of the metadata?
This is something you need to decide for your given project. Yes, there is overhead to store the additional metadata but it does give you the ability to search/filter/fix poisoned data, versus the alternative which you would never have known it was poisoned in the first place. Data lifecycle policies or middleware can also aid in reducing this overhead. You may also have legal obligations to keep the provenance of your data and need to consider moving these to an acceptable storage backup. One good example of a data lifecycle policy is to automatically archive to less expensive storage like tape storage any entry that is one year old. For a system that accumulates 10TB of storage in S3 in a month (at around ~USD 2,760.00 per month) your first month of the next year would only incur ~USD 2,796.00 instead of ~USD 35,916.00. Legal requests won’t have to cost an arm and a leg to serve (just an arm! fingers crossed)
Benefits
When this proposed solution is adopted, it will help trace operational and release issues as well as the PR poison scenario. Adopting this also has wider benefits when scaling to a bigger system with multiple applications and datasets but that’s for another blog post.
Summary
It’s important to keep track of and be able to easily tie the reason, process, source, time, and owner of the application to the application data. It creates an environment where any data problems can be easily traced and extracted to write an isolated fix that doesn’t create cascading impacts to the whole system. For this specific problem where data poisoning occurs during bad migrations, it’s possible to quickly revert bad data if you have data provenance. If you don’t have data provenance then the only way to fix data poisoning is to manually fix them every time they are detected.
Future Discussion
Stay tuned for more posts about how this simple approach can have massive effects on operating and maintaining a huge system! Hint: We’ll be talking about handling multiple data sources as well as multiple applications in a system and handling data poisoning at that level.
Share