Using machine learning to help filmmakers search through videos


Introduction
At Roam we have this awesome initiative called Labs where Roamers have an opportunity to use our downtime productively on self-driven projects to help grow personal and collective capabilities. Labs is a shining example of the company values of a Roamer including curiosity and passion.
This Labs project aimed to investigate how we can use machine learning to facilitate filmmakers searching through large amounts of media assets (e.g. photos, videos) and extract searchable tags. Imagine you have thousands of hours of footage and want to pinpoint the exact scene where “Leonardo DiCaprio is riding his horse into the sunset”.
Background
Images and videos are extremely data-rich. This gave rise to a specialised class of artificial neural networks called Convolutional Neural Networks to capture the spatial features of images inspired by our very own visual cortex. Convolutional layers apply a filter that abstracts patterns and features out of an image and pooling layers help to downsample the data into lower dimension space to reduce complexity. There are a series of convolutional layers that abstracts more and more complex features. For example, the earlier layers may encode edges and shapes and the later layers may encode faces or animals. This process removes the need for manual feature extraction before feeding the output into a fully connected layer.
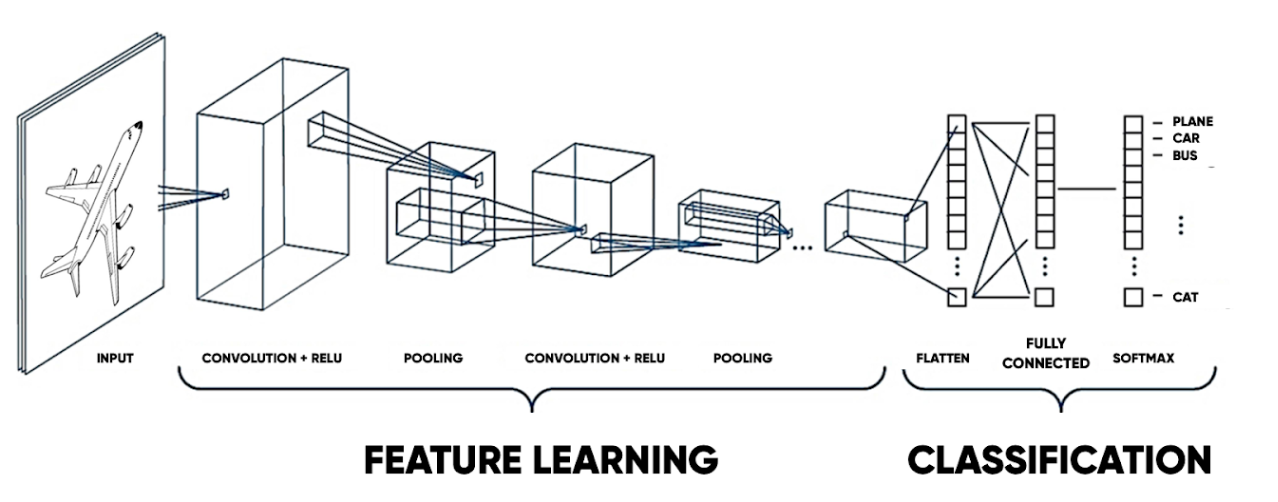
Neural network architecture has got more and more sophisticated and processing power has vastly increased. These networks have evolved from completing simple tasks like image classification (e.g. dog vs. cat) to detecting multiple objects in a scene and image captioning. Later we will also explore how combining these technologies with the advancements in natural-language processing is producing some very impressive results.
3rd Party Services
There are a variety of different services specialised in computer vision tasks. Below we will explore a couple of services to set the baseline on how well these services perform in extracting searchable tags such as objects, celebrities, and captions. The capabilities of the different services in extracting these relevant tags are detailed below.
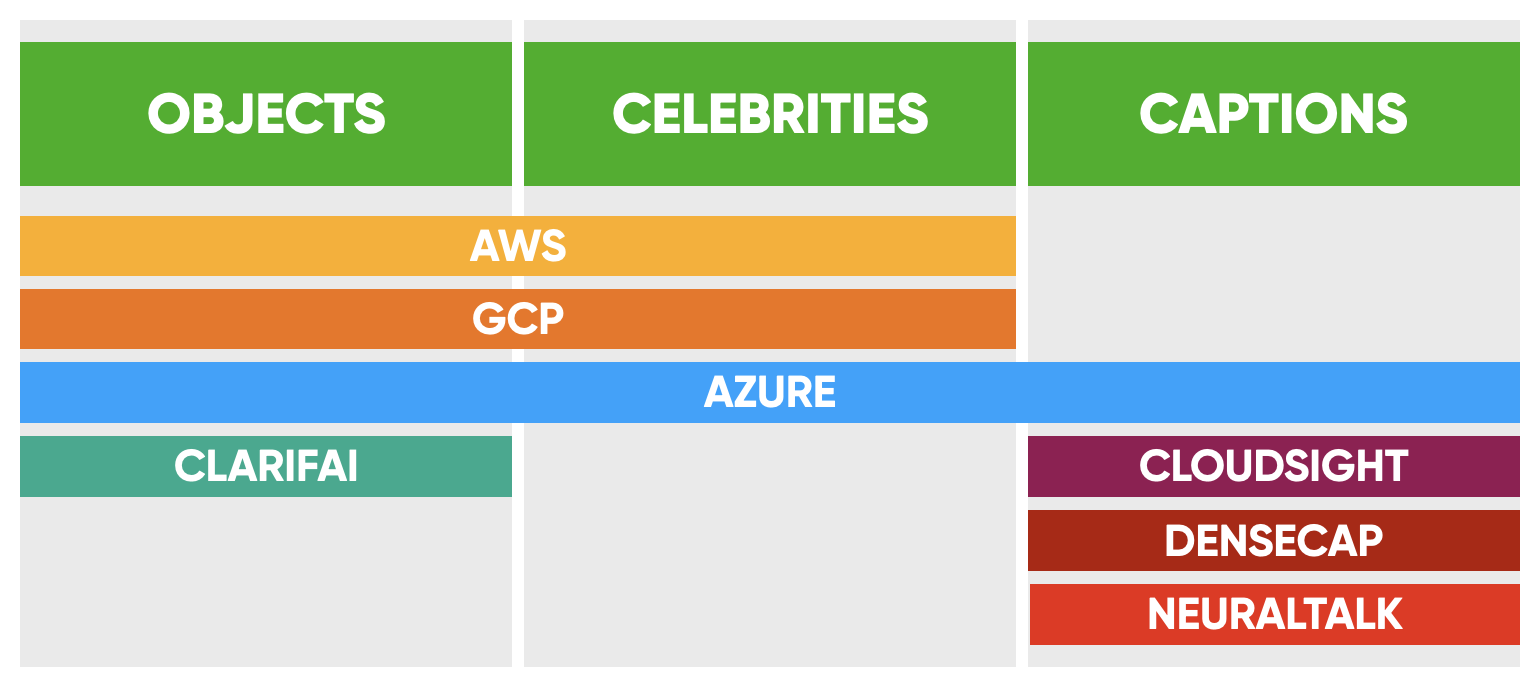
For example take this shot of Nick Jonas on a horse in Jumanji: The Next Level and see how the different services compare.


We get some pretty impressive results, especially from Azure’s image captioning service. It’s hard to demonstrate the capabilities succinctly but after running through a variety of images a few flaws of these services are exposed. These limitations ponder whether we need to break the mould to solve the problem efficiently.
The first problem is that these services can only pick out objects within pre-defined categories inside whatever the training data has been and this can often result in some vague categorisation. For instance, in this scene below the objection detection produces generic results such as face, man, person, and “a group of people standing together”. These vague tags won’t be deemed very useful when it comes to differentiating between scenes.


The second limitation is that these services perform particularly poorly with animated and CGI images. These services have most likely only been trained on natural scene images and suffer significantly with artificial images. In a world of factitious generated content, the ability to decipher between different animated and CGI clips would be of high value.

Finally, there are general inaccuracies to pick up the scene correctly. The tags are binary and misclassifying carries a significant disadvantage to the search indexer. Take below this scene where a letter is burning, instead, objects such as insects and cuisine are extracted.

Open AI - CLIP
Overall it appears the traditional method of extracting humanly understandable tags such as objects, captions, and celebrities may be too binary. A model released in early 2021 called CLIP from Open AI seems to provide a novel approach. The model connects the fields of computer vision directly with natural language understanding. The output of the model is trained to predict where within the “natural language space” the caption occurs. The advancements in natural language processing have meant that language can now be encoded in vector space that calculates the semantic meaning of the text. Essentially, we can put a sentence through an algorithm and it spits out 300 numbers that encode the meaning of the words. Sentences closer in meaning will have numbers that are closer together.
CLIP is trained on 400 million image, text pairs found all across the internet, encompassing a vast array of domains and image types. The network can be “instructed in natural language to predict the most relevant text snippet, given an image, without directly optimising for the task” which is similar to the “zero-shot” capabilities of GPT-3.
The model was trained by splitting the 400 million image, text pairs into batches of 32,768. Images are fed through an image encoder and text captions are passed through a text encoder into their embedding spaces. The image embeddings are then optimised to maximise the cosine similarity to the correct text embedding and minimise the wrong text embeddings in a process called “contrastive pre-training”. Fun fact, the training took 30 days across 592 V100 GPUs - if training on AWS on-demand instances that would have cost over $1 million!
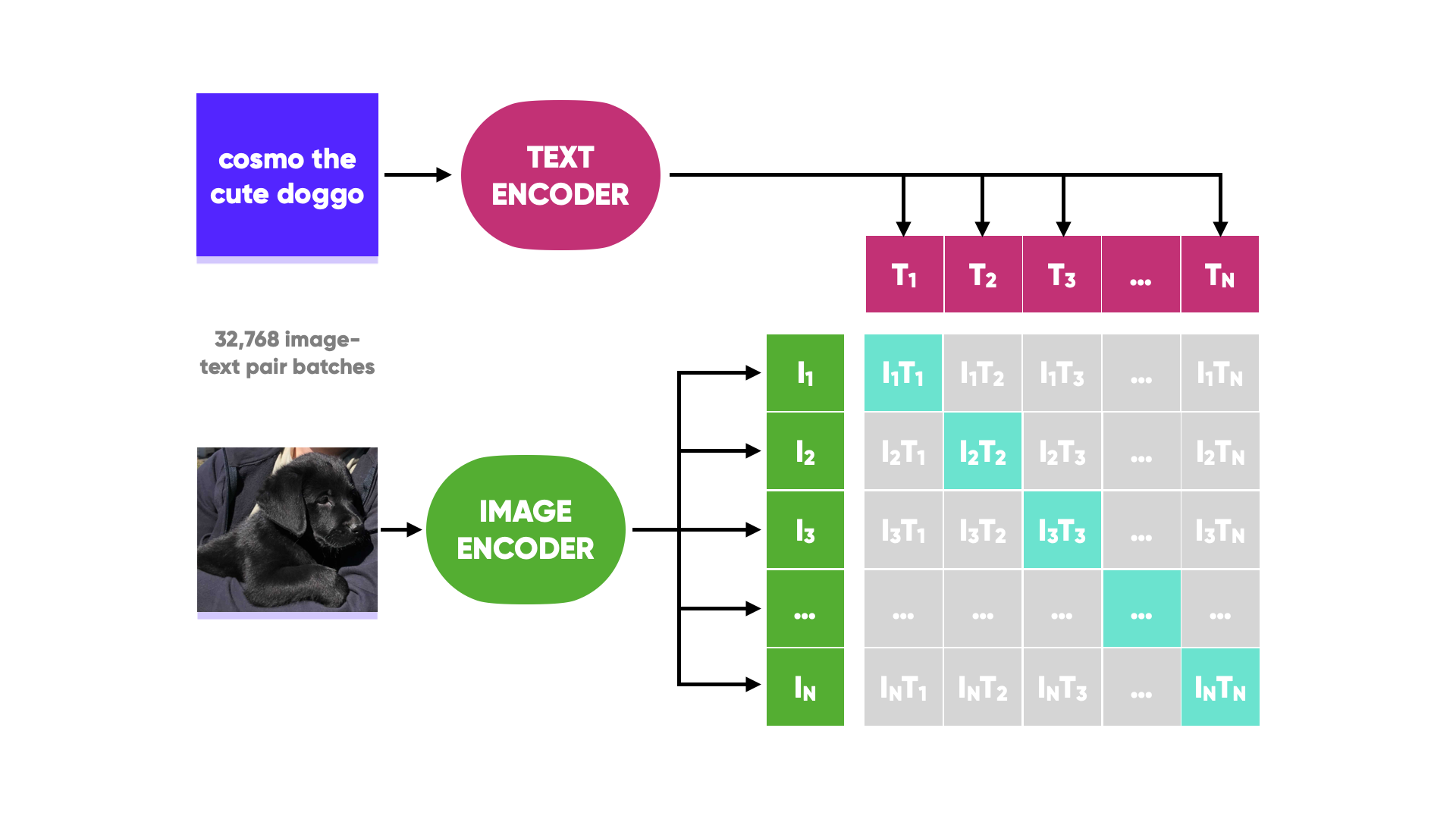
The model typically works by feeding a variety of captions (e.g. a photo of a laptop, a photo of a church, a photo of a dog) and finding the highest scoring caption to an image. However, for our use case, we will flip it around and feed a host of images from videos to find the highest similarity image to the search query, along with a score for each image.

To demonstrate some of the results of CLIP, we will search a few queries across - The Lord of the Rings: The Fellowship of the Ring.


The model produces very impressive results in correctly identifying and understanding scenes. A score of how likely each frame relates to the search query is also visualised below, with yellow indicating the highest probability. This heatmap shows directly where in the movie the scene and most closely related scenes are.
We can take this further and try to search for people. Even though the model has never directly learned who a celebrity or a fictional character is, it can even understand who “Ian McKellen” is and identify the scenes where both the fictional characters of “Legolas” & “Aragorn” are.

There are also additional benefits of CLIP’s understanding of natural language processing and its varied dataset of 400 million image, text pairs. The first is that mis-spellings of words have very similar language embeddings to the correct spellings of words - both would be used in the same context. This means that searching with mis-spellings still results in finding the correct image. Another benefit of the varied dataset is that the model performs very well on a variety of image types, as the internet is flooded with content from pop culture including different domains and mediums. CLIP performs exceptionally better than the other 3rd party services explored before on CGI & animated images. CLIP has also an understanding of named places, celebrities, fictional characters, concepts, feelings, and popular references that have been learned from this vast dataset.



In addition, even though the model was never directly optimised to understand textual characters it is proficient at identifying the relevant text in images. The dataset was most likely littered with examples of text on the image and the corresponding text in the caption. This means the model is very good at finding the relevant images with the text within the search query.

If we go back to the previous example of a generic caption generated by the other third-party services. Now if we employ CLIP to search for “three men giving a news report” - we get a perfect result.


Discovery of multi-model neurons
When researchers broke down CLIP into its composite neurons, they noticed something very interesting. In the human visual cortex, we possess “multimodal neurons” that respond to concepts rather than specific visual features. The most publicised is the “Halle Berry” neuron - that responds to photos of Halle Berry in real life and costume, sketches of her, and even the text “Halle Berry”. CLIP is the first artificial neural network to be discovered that possessed the same ability and has semantic organisation. For example, a “Spider-Man” neuron responds to spider-man in costume, illustrations, and text around spiders. Previous models at the highest levels only encoded high-level visual features (e.g. a face detector).
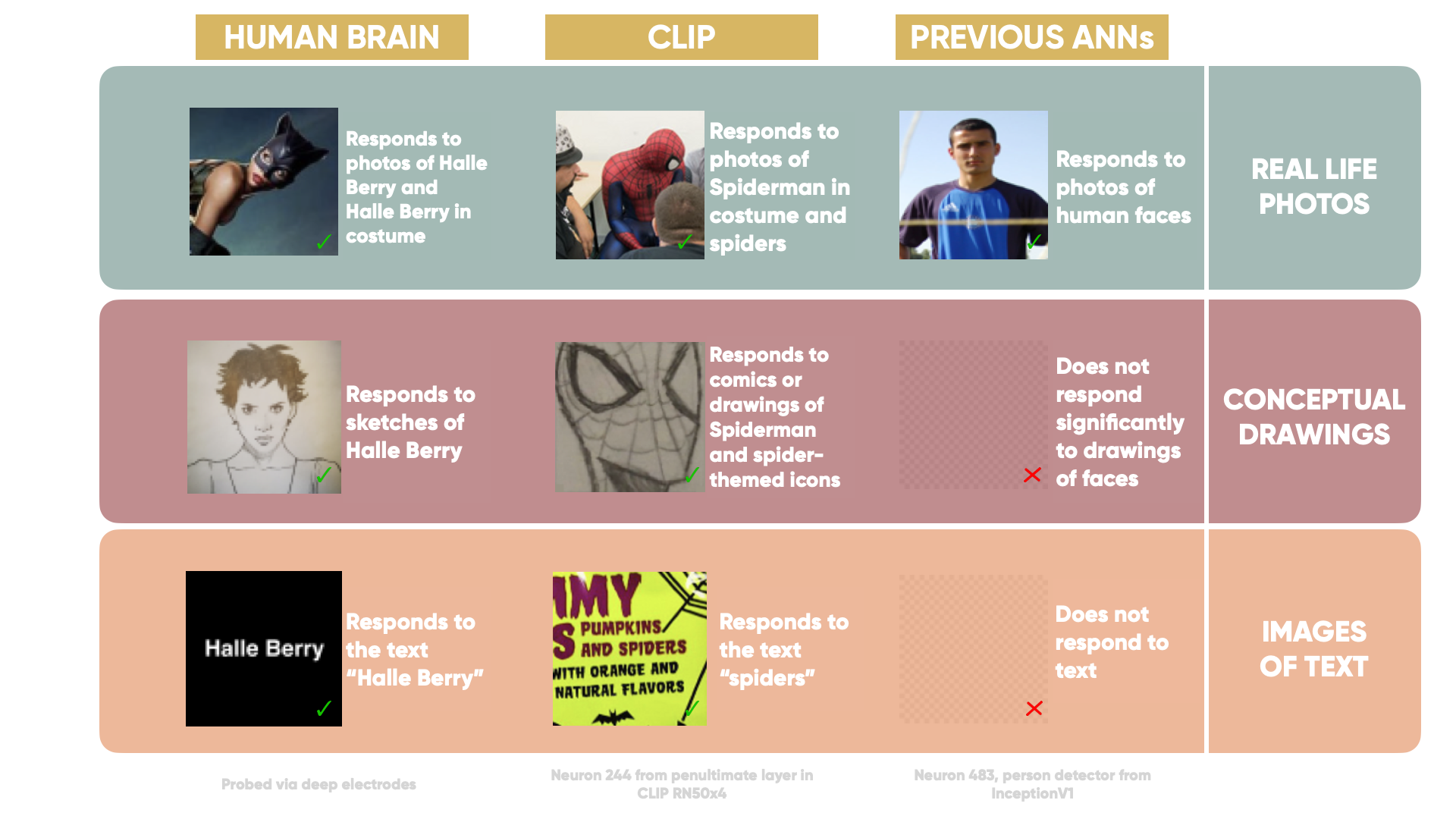
The researchers used two methods to find the multi-modal neurons. The first was to artificially generate images that stimulated each neuron the most, these result in some pretty trippy photos. The second was to find the images in the training data that activated each neuron the most. The combination of these two methods reveals a whole host of different multimodal neurons from geographical regions, to famous people, and fictional universes. They have published the model’s neurons here for users to go in and explore themselves. A few examples of emotion, region, holiday, and person neurons can be seen below. Below are examples of artificially generated images to maximally stimulate that neuron.

Limitations of CLIP
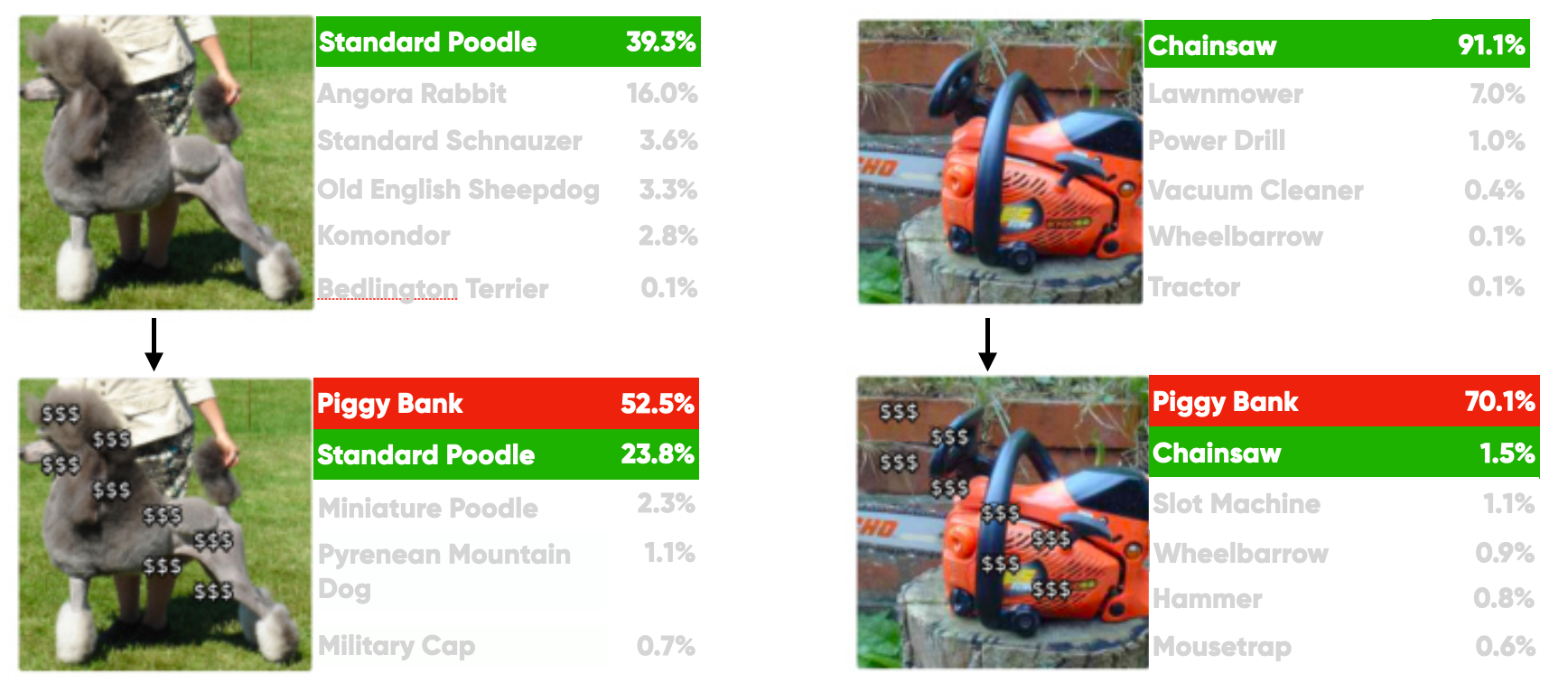
Nothing is perfect and CLIP suffers from a few limitations. The first is completing systematic classification, CLIP performs poorly on tasks such as counting the number of objects or fine-grained classification (e.g. different cars or birds). The second is the poor generalisation to types of images not covered in its pre-training dataset, for example, the model’s accuracy is only 88% on the MNIST dataset which naive machine learning algorithms can score 99-100%. CLIP would not have high accuracy for specific use cases such as classifying medical scans or reading street view house numbers. CLIP also demonstrated sensitivity to “typographic” attacks. The model is heavily biased by text in an image and this can result in some interesting results. Such as putting dollar signs on a chainsaw and the model misclassifying the image as a piggy bank.
Conclusion
The coupling of natural language understanding and computer vision provides the strongest results in our original aim. CLIP appears to have the highest versatility as it is not confined to binary tags and has been trained on most likely the largest dataset. CLIP was used in tandem to generate the image generation model that has recently blown up the internet - DALL.E 2. The combination of computer vision and natural language processing is producing some very exciting new technologies and it will be an area to keep an eye on!
Share